Episodio II: Vestizione dei dati vettoriali
La Scheda Simbologia ti fornisce uno strumento completo per la visualizzazione e la vestizione dei dati vettoriali. Le diverse opzioni di vestizione dei dati vettoriali si trovano all’interno della finestra di dialogo Proprietà. Seleziona dalla spalla sinistra il sotto menù simbologia. Tutte le tipologie di vestizione condividono la seguente struttura della finestra di dialogo: nella parte superiore, disponi di un widget che ti consente di impostare il tipo simbolo e la classificazione per le geometrie e nella parte inferiore il widget Visualizzazione del layer.
Indipendentemente dal tipo di geometria del vettore, esistono quattro tipologie comuni di visualizzatori:
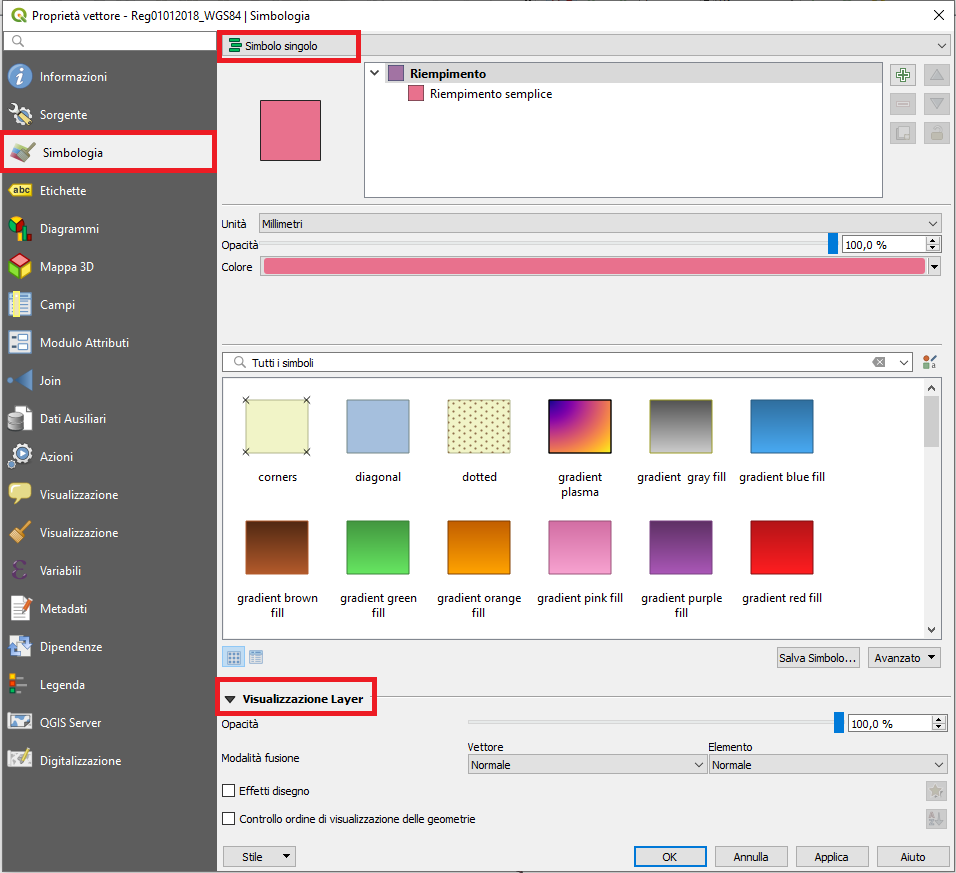
1. Simbolo Singolo, questa opzione permette di scegliere un singolo stile che verrà applicato a tutte le geometrie del layer. Se ad esempio lavoriamo con un layer poligonale possiamo lavorare sullo stile di riempimento del poligono e sulle linee del bordo. Possono essere cambiati i pattern di riempimento utilizzando quelli forniti di default.
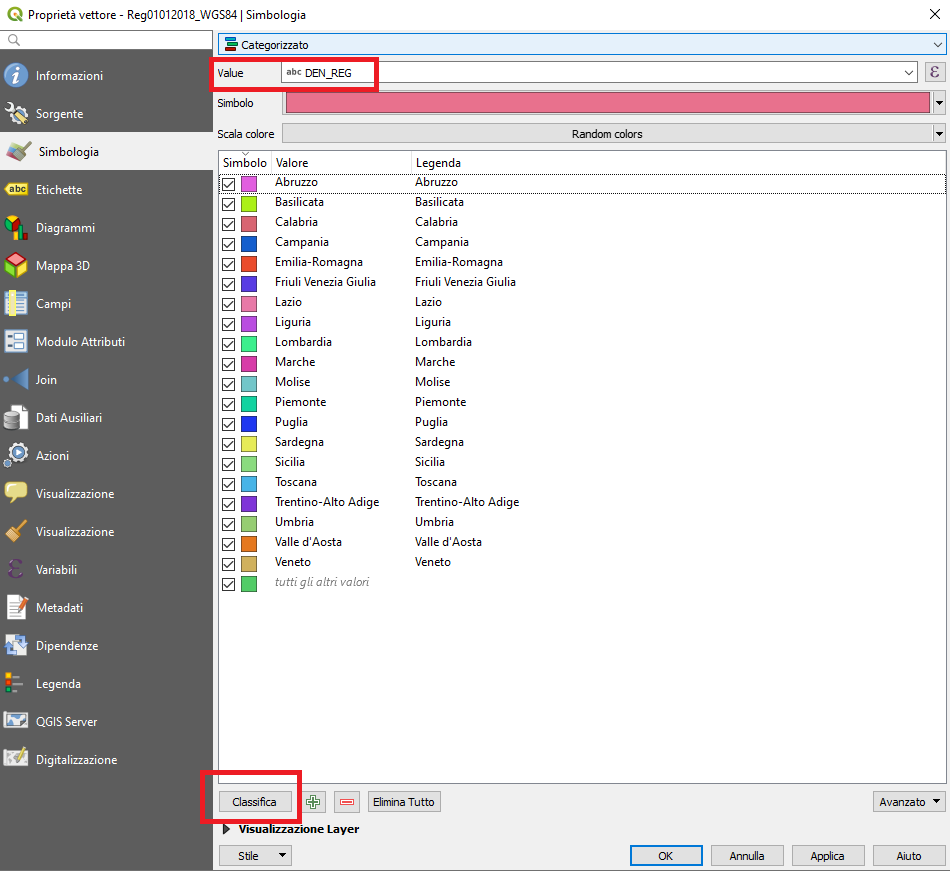
2. Categorizzato con questa opzione le geometrie saranno presentate in diverse gradazioni di colore sulla base dei valori univoci degli elementi di un campo della tabella attributi. E’ una rappresentazione adatta per visualizzare i valori discreti e categorizzati di un database.
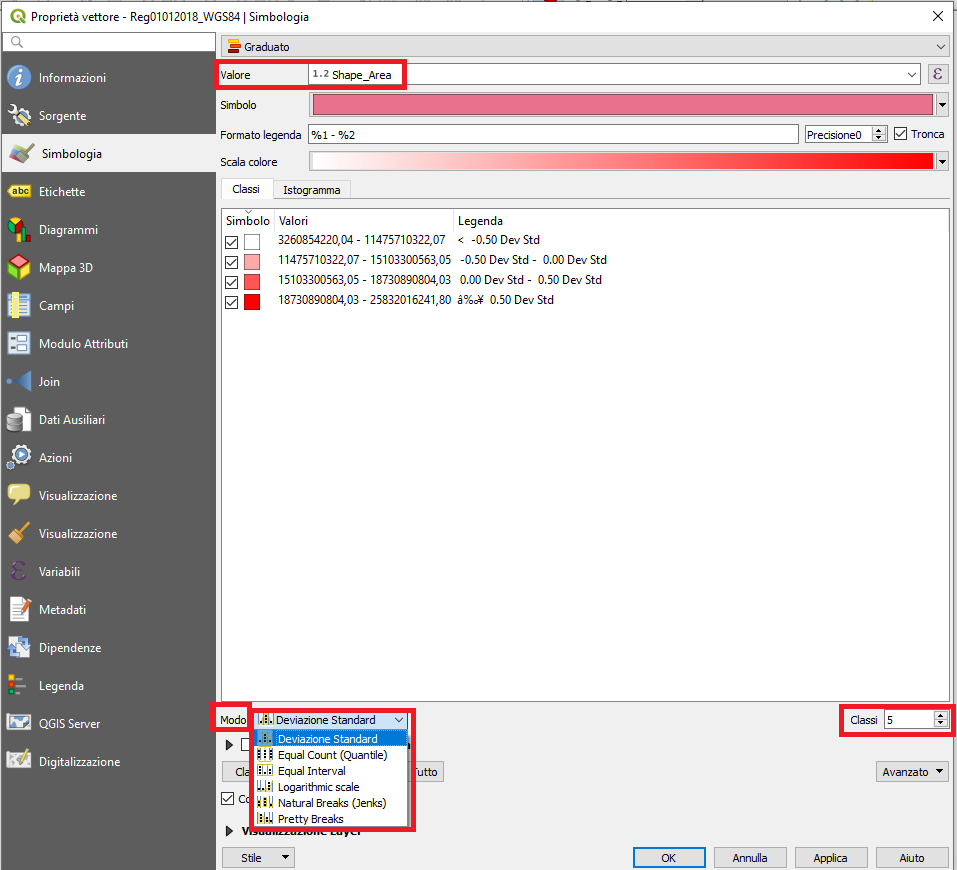
3. Graduato ci permette di suddividere i dati raccolti in una colonna della tabella attributi in un certo numero di classi. Questa metodologia di classificazione si basa solo su campi numerici. Esistono diversi modi di classificazione che utilizzano algoritmi statistici diversi per suddividere i dati in classi, QGIS fornisce 5 modi:
- Intervallo uguale, questo metodo creerà classi che sono della stessa misura
- Quantile, questo metodo definisce delle classi di intervallo tali per cui il numero dei valori in ciascuna di esse sia lo stesso. Se ci sono 100 valori e noi vogliamo suddividerli in 4 classi il metodo del quantile stabilirà intervalli di valore pari a 25 ciascuna
- Naturals Breaks, questo algoritmo si propone di individuare dei raggruppamenti naturali dei dati per creare le classi di intervallo. Le classi saranno tali che ci sarà una varianza massima tra le singole classi e una minima varianza all’interno di ciascuna classe
- Deviazione standard, questo metodo calcolerà la media dei dati e creerà le classi sulla base della deviazione standard dalla media
- Pretty Breaks, questo metodo è basato su un pacchetto statistico chiamato R pretty algorithm. É piuttosto complesso ma l’algoritmo crea delle classi confine intorno ai numeri.
Utilizzando la voce “classi” può esserne settato il numero in cui vogliamo suddividere la nostra visualizzazione. Facendo poi doppio click sui singoli simboli è possibile scegliere uno stile differente per ogni classe e modificare i valori massimo e minimo dell’intervallo.
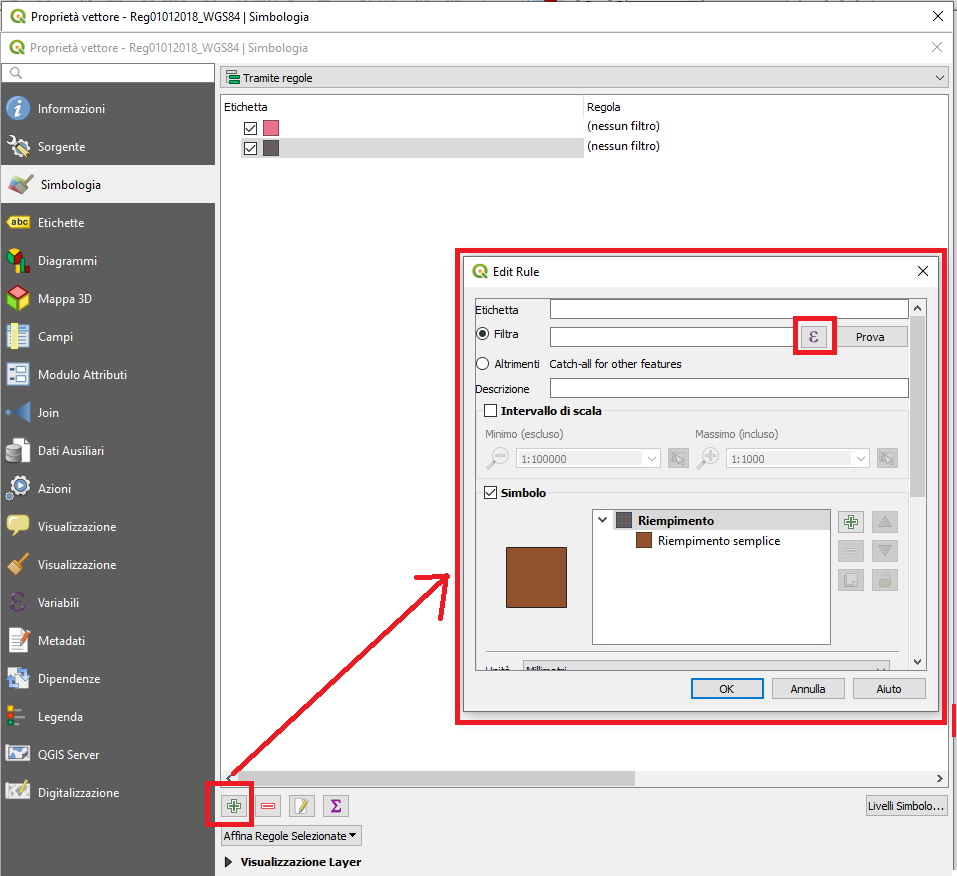
4. Tramite regole viene utilizzato per eseguire la visualizzazione di un layer, utilizzando simboli basati su regole il cui aspetto rispecchia l’assegnazione dell’attributo di una geometria selezionata di una classe. Le regole sono basate su istruzioni SQL. La finestra di dialogo consente di definire le regole per filtrare il raggruppamento o condizionare la visualizzazione alla scala.